
基于恒模复值神经网络的正交相位编码集设计
2024-01-05 08:36邱明劼王建明伍光新
现代雷达 2023年11期
邱明劼,王建明,伍光新,张 鹏
(1. 南京电子技术研究所, 江苏 南京 210039)
(2. 中国电子科技集团公司电子科学研究院, 北京 100041)
0 引 言
多输入多输出(MIMO)的思想起源于多变量控制理论,并在20世纪90年代被应用于通信领域[1]。鉴于MIMO技术在通信领域发挥了巨大作用,研究学者们将其概念扩展到了雷达探测领域[2]。经过长期发展,人们对MIMO雷达系统的基本原理和阵列信号处理进行了充分研究,并且随着数字信号处理和大规模集成技术的成熟,MIMO雷达已成为雷达行业创新且有前景的前沿研究领域[3-5]。
与传统相控阵雷达每次发射特定波形不同,MIMO雷达可以通过不同的发射阵元同时发射不同的波形,在接收端通过匹配滤波将所有波形分离,并进行联合处理。采用正交波形发射时,MIMO雷达具有比传统相控阵雷达更高的分辨率[6]、更好的信噪比改善[7]和更灵活的发射方向图[8]等诸多优势,这使得设计具有良好相关特性的正交波形集成为了关键[9-11]。
由于无法设计出具有完美相关特性的正交集,因此通常采用最小化代价函数的方式逼近完美特性,常见的代价函数包括累计副瓣电平(ISL)[12]、加权累计副瓣电平(WISL)[13]和峰值副瓣电平(PSL)[14]。文献[15]基于PSL和ISL共同构建了代价函数,并采用模拟退火(SA)搜索算法进行优化,文献[16]和[17]中则使用了遗传算法(GA)来对编码集进行优化。文献[18]提出了由波形协方差矩阵(WCM)合成编码集的循环算法(CA),并被文献[19]进一步改进为新的循环算法(CAN),使得设计得到的正交相位编码集具有更好的相关特性。
随着计算机的发展,神经网络在雷达系统设计和信号处理等领域得到了广泛的应用[20-22],复值神经网络(CV-NN)也逐步被用于雷达通信领域的信号处理[23]。本文也进行了相关尝试,提出了一种基于恒模复值相关性神经网络(CMCV-CorrNN)进行正交相位编码集设计的方法。为保证模值恒定,CMCV-CorrNN没有像传统方法那样将复值权值划分为实部和虚部进行训练[24-26],而是对相位分离后单独训练。仿真实验结果表明,所提方法可以在不受编码序列长度、集合内编码序列数量限制的情况下,获得比CAN等现有先进方法相关性更好的正交相位编码集。
1 问题描述
对于一组正交波形,相关特性包含自相关特性和互相关特性两个部分。当每个信号波形都与其自身的非零时移不相关时,称该波形集具有良好的自相关特性;当任意两个波形与对方任意的时移均不相关时,称其具有良好的互相关特性。如果将一个由L个波形组成的集合记为{sl(t),l=1,2,…,L},其中t为时间,则上述相关特性可以表示为[27]
(1)

(2)
式中:p=1,2,…,L;q=1,2,…,L;E为信号能量;τ表示时移;为实数域;“*”代表取复共轭。
在实际应用中,如果集合中所有波形都是通过相位调制产生的,则该集合称为正交相位编码集。假设一个正交相位编码集由L个离散时间序列组成,每个序列长度为N,则集合中的第l个序列sl可以表示为列向量,即
sl=[exp[jφl(1)], exp[jφl(2)], …, exp[jφl(N)]]T
(3)
式中:j为虚数单位;φl(n)∈[0,2π],是第l个序列中第n个子码的相位。
因此,编码集可以表示为N×L复值矩阵,即
(4)
式中:第l列的值即为编码集的第l个序列。
根据式(1)、式(2)和式(4),该正交编码集的自相关函数A(sp,k)和互相关函数C(sp,sq,k)应该满足
A(sp,k)=
(5)
C(sp,sq,k)=
(6)
式中:p=1,2,…,L;q=1,2,…,L;sp和sq分别表示集合的不同序列;k表示时移。
如前文所述,一般通过最小化代价函数的方法对正交相位编码集进行优化,其中,ISL能够反映两个序列相关性的整体性能,是最常用的代价函数,可表示为
(7)
由于编码集内两个不同序列任意时移的互相关结果都可认为是副瓣,因此将ISL扩展到互相关函数得到累积电平(IL)。
(8)
式中:p≠q;p=1,2,…,L;q=1,2,…,L。
综合式(7)和式(8)可以得到用于评价正交相位编码集整体相关性的代价函数,即
(9)
编码集的优化是一个不断减小代价函数的值,使其接近于0的过程。一旦将编码集的所有序列作为网络权值,单一序列作为输入,该过程就可以看作是神经网络的训练过程。对于作为输入的第l个序列(长度为N)而言,网络的期望输出是只在第l个输出神经元的第N个输出为1,而其他位置或其他神经元的输出均为0。
2 恒模复值相关性神经网络
基于上述分析,本文提出了一种恒模复值相关性神经网络(CMCV-CorrNN)来进行正交相位编码集设计。
2.1 CMCV-CorrNN的结构
根据正交相位编码集的优化过程与神经网络训练的相似性,构造的CMCV-CorrNN结构如图1所示。

图1 恒模复值相关性神经网络结构
2.1.1 输入层
输入层只包含一个神经元,每次接收编码集中的一个复数序列作为网络的输入。在训练过程中,编码集中的每一个序列依次通过输入层的神经元进入到网络进行训练。当使用第l个序列作为输入时,这一层的输出记为向量il。
2.1.2 隐藏层(相关层)
隐藏层包含L个神经元,其数量等于集合中序列的数量,该层用于计算编码集的互相关函数。因此,直接使用编码集中的序列作为每个神经元的权重模板,就可以在这一层的输出端获得输入序列的自相关函数和互相关函数。对于该层的第l个神经元,其输出记为vl。
2.1.3 输出层
输出层同样包含L个神经元,用于对相关层输出进行取模运算。经过该层后,所有输出都转换为实数,这有利于后续损失函数的计算。对于该层的第l个神经元,其输出记为ol。
2.2 网络输入和输出
网络的输入是编码集中的序列,每个序列均为1×N的行向量。每轮训练时,编码集中的所有序列按顺序逐个作为输入使用。
对于每个输入,在输出端都将得到L个长度为2N-1的行向量。其中,第l个神经元的输出是输入序列与编码集中第l个序列之间的互相关函数的模。如果输入恰好是编码集中的第l个序列,那么第l个神经元的输出就变成了其自相关函数的模。
2.3 前向传播过程
在前向传播之前,用N×L个模为1且相位随机的复数对隐藏层权值进行初始化。当选取第p个序列ip作为网络输入时,根据互相关定义,输入ip和第l个神经元权值wl的互相关函数的第n个值可以表示为
(10)

隐藏层的第l个神经元的输出可以写成如下的矩阵形式
(11)
然后在输出层,通过计算隐藏层输出的模,得到网络的最终输出。对于输出层的第l个神经元,取模运算为
(12)
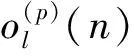
为了获得更好的相关性,目标真值通常设为正交编码集的理想自相关和互相关结果,即当输入为该编码集的第p个序列时,第l个神经元的第n个元素的目标真值为
(13)
式中:l=1,2,…,L;p=1,2,…,L;n=1,2,…,2N-1。
2.4 后向传播过程
通过将目标真值与实际网络输出相减,即可得到当前网络的误差,并选择均方误差(MSE)函数作为网络的损失函数,即
(14)
式中:O(p)为第p个序列作为输入时网络输出构成的矩阵,p∈[1,L]。系数1/2用于对后续计算过程进行简化。
通过对比式(9)和式(14)可以发现,当输入序列ip确定且目标真值设置为理想输出时,二者等价。
接着,采用基于随机动量梯度下降(SGDM)对网络进行训练。根据链式法则,当第p个序列作为输入时,损失函数关于权值wl(n)的梯度可以表示为
(15)
式中:n=1,2,…,N。
(16)
根据式(12),输出层将复数转换为实数,则在后向传播时就需要将向后误差从实数重新变回复数。为避免传统方法将该过程拆分为实部和虚部分别计算的问题,将取模运算表示为复数与其自身复共轭的乘积的开方,即
(17)
则输出层的梯度即可表示为
(18)
从而避免在计算输出层梯度时分为实部和虚部分别计算。
考虑复数的指数表达形式
c=R(c)+jI(c)=Acexp(jφc)
(19)
式中:Ac和φc分别是复数c的幅度和相位。
结合式(15)、式(18)和式(19),隐藏层的梯度可以分为如式(20)和式(21)所示的幅度和相位两部分。
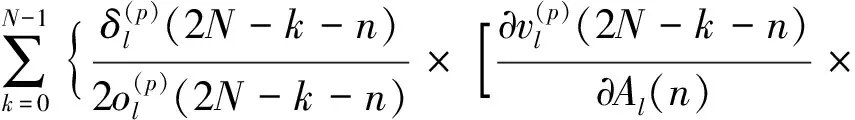
(20)
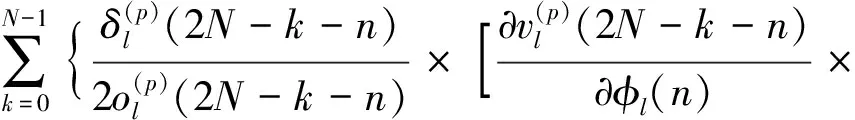
(21)
考虑恒模约束
Al(n)≡1
(22)
式中:Al(n)为第l个权值模板中第n个元素的幅值;l=1,2,…,L;n=1,2,…,N。
在恒模约束下,式(20)恒等于0。将式(11)带入式(21)可以得到
(23)
(24)
然后将式(23)和式(24)代入式(21),即可得到后向传播梯度的最终表达式

(25)
最后,按照式(26)、式(27)更新权值wl(n)的相位
(26)
φl(t+1)=φl(t)-ηΔφl(t)
(27)
式中:t表示训练轮次;β表示动量参数;η表示学习率;φl(t)表示第t轮训练中第l个模板第n个元素的相位。为避免元素序号n与神经网络的训练轮次混淆,在此处将n省略。
综上所述,使用本文提出的复值网络设计的正交相位编码流程如图2所示。

图2 本文所提方法流程图
2.5 训练参数
网络的训练参数如表1所示。

表1 CMCV-CorrNN的参数
从式(25)可以发现,后向传播时梯度的幅值与编码集中序列的数量L呈反比例,因此此处将学习率η乘以L,以确保对于具有不同序列数量的编码集,网络能够以近似恒定的速度收敛。
3 仿真结果与分析
为充分验证本文所提方法设计的正交相编码集性能,本节设计了一系列不同N和L取值的编码集,并使用自相关副瓣峰值(ASP)和互相关峰值(CP)作为编码集相关性的评价指标。
(28)
(29)
式中:p=1,2,…,L;q=1,2,…,L;k表示离散时间。
作为对比,选取了三种代表性算法SA[12]、CAN[20]和Legendre序列(L-seq)[9]与本文方法进行比较。所有编码集设计结果都使用搭载主频为3.6 GHz的Intel®CoreTMi7-4790中央处理器和GeForce RTX 3060显卡的计算机处理得到。
表2显示了(N,L)=(32, 4)条件下,使用本文方法设计的正交相位编码集中各序列相位值,编码集的ASP和CP如图3所示。从图3可以得到,该编码集的平均ASP值约为-16.10 dB,平均CP值约为-15.65 dB。
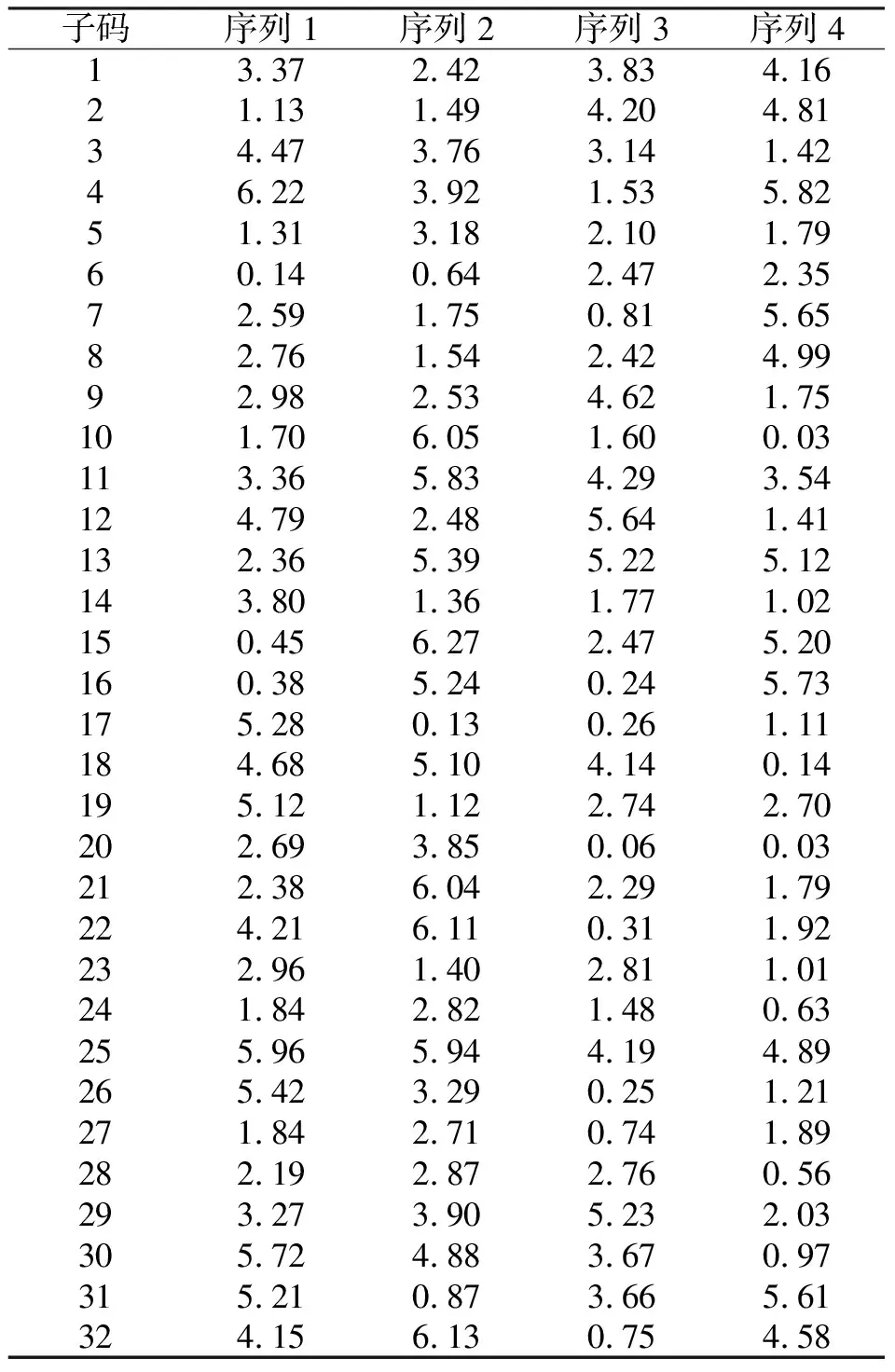
表2 (N,L)=(32,4)条件下本文方法设计的编码集相位值

图3 (N, L)=(32, 4)时以dB表示的设计编码集的ASP和CP
为了直观展现本文方法所设计的正交相位编码集所具有的良好相关性,在(N,L)=(128, 3)条件下设计的编码集的自相关函数和互相关函数如图4所示。对于该编码集,ASP最大值为-21.92 dB,平均值为-22.29 dB,CP最大值为-22.19 dB,平均值为-22.34 dB。

图4 (N, L)=(128, 3)条件下设计编码集的自相关和互相关函数
图5显示了在(N,L)=(128, 3)例子中损失函数值随训练次数变化的过程。

图5 损失函数随训练次数的变化
从图中可以看出,随着网络训练的进行,损失函数迅速减小,网络快速收敛,正交相位编码集的相关性持续改善。
表3给出了在不同N和L情况下,本文方法与3种先进算法设计的正交相位编码集的平均ASP和CP值。从表中可以看出,不论在何种情况下,本文所提方法设计的编码集的平均ASP值和CP值均优于其他方法的设计结果。此外,在编码集中序列数量L不变时,随着序列长度N的增加,ASP值和CP值均逐步降低,当N从64增加到1024时,ASP值由-19.41dB降低到-30.93 dB,CP值由-19.17 dB降低到-30.91 dB。同时,在序列长度N不变的情况下,随着编码集中序列数L的增加,ASP值和CP值缓慢上升。

表3 不同情况下4种算法设计结果的平均ASP值和CP值对比
图6显示了当编码集内序列数量固定为3,序列长度从16变化至4 096时,使用本文方法和使用L-seq方法得到的编码集的平均ASP值和CP值。从图中不难看出,随着序列长度的增加,两种方法设计得到的编码集的ASP值和CP值均单调下降,但在相同条件下,本文方法所得编码集的ASP值和CP值均始终优于L-seq方法的设计结果。

图6 在L=3情况下,编码集的平均ASP和CP值
为检验本文所提方法的稳定性,在(N,L)=(64, 3)情况下,使用本文方法进行了100次正交相位编码集设计仿真。每一次仿真时,网络的权值均重新随机生成,100次仿真结果得到的正交相位编码集的ASP和CP值如图7所示。

图7 (N,L)=(64,3)时100次仿真设计结果的ASP和CP值
从图中可以看出,尽管每次仿真中网络的初始权值是随机的,但经过训练后,最终得到的ASP值和CP值几乎没有变化,稳定在-19 dB左右。由于网络的训练次数始终固定为300,因此图7表明,本文所提出的CMCV-CorrNN方法能够在给定周期内稳定地设计出相关性良好的正交相位编码集。
4 结束语
本文创新地提出了一种使用复值神经网络进行正交相位编码集设计的方法。该方法把正交相位编码集的设计看作是对非线性系统的拟合过程,将编码序列作为网络的权值进行训练,同时通过分离幅度和相位的方法确保仅对相位进行优化,从而保证了在整个训练过程中网络权值的幅值始终恒定。
在实验仿真部分,通过与现有的先进算法进行比较,验证了本文所提方法能够得到相关特性更好的正交相位编码集,证明了所提方法的有效性。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
自然杂志(2021年6期)2021-12-23
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
现代装饰(2018年5期)2018-05-26
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
