
基于encoder-decoder 框架的城镇污水厂出水水质预测
2023-11-27 06:06史红伟王云龙李鹏程
中国农村水利水电 2023年11期
史红伟,陈 祺,王云龙,李鹏程
(1.长春理工大学电子信息工程学院,吉林 长春 130022;2.长春水务投资发展集团有限公司,吉林 长春 130022)
0 引言
伴随着城镇化的快速发展和城镇人口的急剧增加,城镇的污水量急剧增加,污水处理压力大增。多数污水处理厂存在水质不确定性高,工艺优化困难的问题。为实现工艺优化,需要展开工艺参数对出水水质影响的研究,实现以工艺和环境参数为依据的出厂水质预测,再根据预测情况实时调整污水处理工艺,使得污水处理过程在保证污水处理效果的前提下兼顾水资源治理和节能减排的需求。目前我国县一级已普及污水处理厂,且多采用CASS 工艺进行污水处理[1]。CASS 工艺具有占地少、效率高等特点,与MBR、A2O 处理工艺相比,CASS 工艺采取间歇式处理,其工艺调整更加复杂[2],目前并没有针对CASS 工艺污水处理出水水质预测方法的研究。
现有的预测模型主要分为3 种:基于确定生化反应的机理模型、基于传统统计学的预测方法、基于数据驱动的机器学习模型。其中,基于确定生化反应的机理模型需要对污水处理过程中的生化反应进行建模,但由于污水指标众多且污水处理过程中反应复杂,导致这类模型预测准确度不高[3]。基于统计学的预测模型是对影响污水厂出水的各个因素与污水厂出水之间的影响因子建立的数学统计模型,由于影响污水厂出水水质的因素众多且污水数据非线性程度高,所以这类模型难以取得较好的预测效果[4]。基于数据驱动的机器学习模型是指仅需确定模型输入输出类型、而无需机理过程就能建立非线性模型[5],因此这类模型在面对复杂问题时具有较好的预测效果,特别是在过去数年中,算力快速提升使得机器学习发展更加快速,应用更加广泛,在水质预测[6]、PM2.5[7]、风电功率[8]方面取得了较好效果,ELSARAITI M[9]使用LSTM 来建立时间序列的预测模型,与统计学方面的模型(ARIMA)相比,预测的误差更小,精度更高。近年来更多的学者将机器学习应用与污水厂出水预测方面,陈威等[10]使用人工神经网络建立污水出水水质预测模型,能对出水COD 和NH3-N 预测变化趋势进行较好的预测,但对局部指标变化预测效果欠佳;林佳敏[11]等将BP 神经网络和ARIMA 结合,姚怡帆[12]利用Stacking 集成思想结合多种机器学习方法对出水总氮进行预测,相比与单一算法预测效果更佳,但这种结合多种算法的预测模型相比于单一模型更容易过拟合,对样本质量要求更高,同时对计算资源和时间的要求较高。上述模型进行预测时只采用污水处理厂监测到的数据,而忽视了污水处理过程中环境因素的影响,因此本文将影响污水处理过程的因素序列引入一同计算,从而进一步提高污水出水预测准确率。
本文使用机器学习中的神经网络来进行水质预测,在序列预测问题中,最常使用的是RNN 及其变种[13]。在黄河水质[14]和光伏电压[15]这一类复杂序列上先利用CNN 提取特征后再由RNN 进行预测,可以得到比单RNN 网络更精准的预测结果。由于污水出厂水质指标复杂、时序非线性程度高、污水处理过程中反应复杂无序等问题,简单的顺序结构神经网络难以进行准确预测。因此,本文提出了一种基于encoder-decoder 结构的神经网络,这一结构可以很好解决复杂序列问题[16,17]。此结构在复杂水质预测应用中,由厂入水处与厂出水处两点的多个水质指标而建立。encoder 的输入为厂入水处历史结构和影响污水处理过程的因素,decoder 的输入的为厂出水处历史数据,decoder 输出为厂出水处未来水质指标预测数据。将实际采集到的数据输入到神经网络中进行学习,经过学习后的神经网络可以很好的再现水质变化的动态过程,获得一种能高效准确预测污水厂出水水质的模型,可以为后续的工艺优化和模型预测控制提供很好的前提支撑。
1 基于ED-GRU网络的污水水质预测方法
1.1 GRU网络结构及其工作原理
本文采用门控循环神经网络(Gated Recurrent Unit,GRU)组成encoder-decoder 结构的神经网络,其中GRU 是Cho 等[18]在2003年提出的一种LSTM 神经网络的简化网络。相比于LSTM结构的3 个“门”,GRU 将其简化至两个“门”:“更新门”和“重置门”。单个GRU 如图1所示,其主要组成为重置门和更新门。因为使用的门结构更少,GRU 参数更少,计算过程简化,比LSTM模型训练更快。
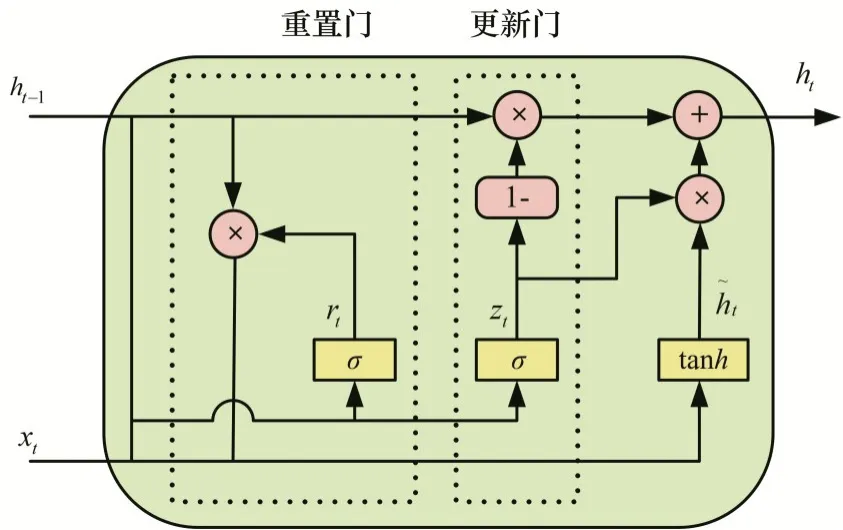
图1 GRU神经网络Fig.1 GRU Neural Networks
1.2 encoder-decoder结构
编码器-解码器是神经网络的一种框架结构,广泛应用于机器翻译、文本识别、语音识别[19]。通过encoder 提取丰富的特征并生成包含输入的全局信息的矢量C,然后将矢量C 输入到decoder 中,最后通过encoder 解码得到预测数据。在多指标预测时由于输入输出长度不同会导致某些预测指标效果不佳,在encoder-decoder 结构中将影响出水水质的因素通过encoder 编码成一个向量后再输入到decoder 中,而decoder 第二路输入和输出长度一致从而避免预测效果失衡。在长期预测中由于常见包含RNN 及其变种的算法在预测多步时间序列时会将上一次预测值作为历史数据而导致之后预测数据误差越来越大,而解码器编码器将时间序列表达为向量进而避免这种问题。
1.3 ED-GRU
文中ED-GRU 模型的结构如图2所示。首先,定义一个单层GRU 作为编码器对影响厂出水水质的其他因素(入厂水水质、环境)的历史数据进行编码。然后,定义一个单层GRU模型作为解码器,该解码器有两个输入,一个输入为通过编码器对影响厂出水水质的其他因素历史数据提取出的全局信息,另一输入为厂出水历史数据,最终通过解码器输出厂出水未来预测数据。其中n代表历史数据步长,m代表预测未来数据步长。
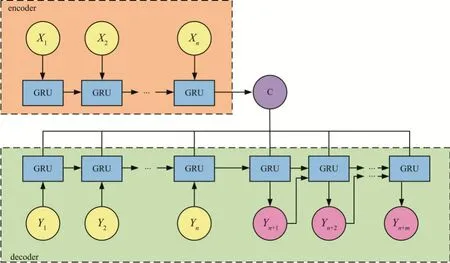
图2 ED-GRU神经网络Fig.2 ED-GRU neural network
2 水质指标及其影响因素分析
模型采取多指标预测策略,需要对每个输入输出进行指标选择。根据城镇污水处理厂排放标准(GB18918-2002)[20],城镇污水处理厂出水处需要对COD、BOD5、SS、TN、TP、NH3-N、pH等指标进行实时监测。为了研究厂出水指标内的时序关系,本文将以上指标的历史值作为decoder的另一输入,以上指标的预测值作为模型输出。但实际生产过程中,由于设备或人为因素导致部分厂出水水质指标无法采集或数据大幅度异常。为了提高预测准确度,本文从污水处理过程中的生化反应方面选择影响出水水质的因素。污水处理生化反应过程中,进水水质作为反应物对生成物(出水水质)有着决定性影响。此外,降水量、温度等环境因素也会影响生化反应物载体活性污泥处理效率和出水水质[21]。因此,将厂入水处水质和环境因素的历史指标作为encoder 输入,通过encoder 编码后提取出这些影响因素对厂出水影响因子的全局向量,进一步提高模型在复杂环境下的预测性能。该模型具体数据划分如图3所示。
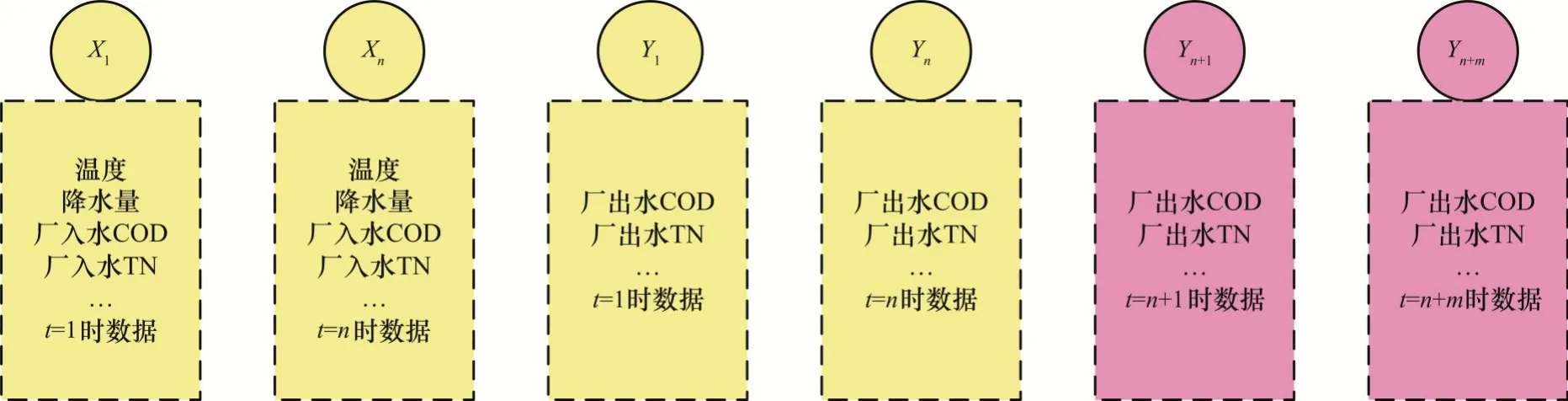
图3 神经网络输入输出数据划分Fig.3 Neural network input and output data division
3 实验方法与数据划分
3.1 实验设计
以GRU 神经网络作为编码器和解码器按照encoder-decoder结构构建了一种污水厂出水水质预测模型。实验模型为EDGRU、ED-LSTM,通过与顺序结构的GRU、LSTM 模型对比来验证encoder-decoder结构模型的性能。
为了更好的对比模型性能,本文从两个不同的时间维度(短期预测和长期预测)对模型性能进行分析。其中,短期预测更偏向模型对污水水质局部变化的预测能力,而长期预测更倾向模型对未来水质总体趋势的预测能力。其中均采用步长为20 的历史数据(n=20),短期预测采取步长为1 的未来数据(m=1),长期预测采取步长为20的未来数据(m=20)。将由上述4个模型分别进行短期和长期预测,通过参数对比获得最优模型。
3.2 实验流程
为了得到最优模型,需要在训练过程中对模型参数进行一些调整,具体实验流程如图4所示。
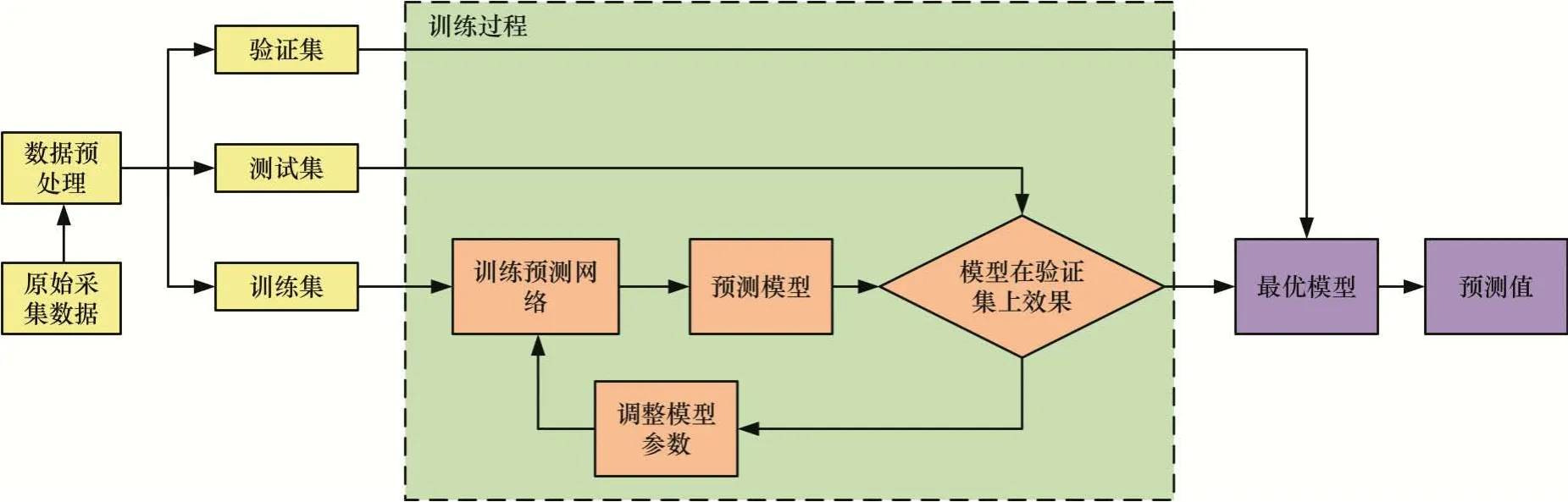
图4 实验流程图Fig.4 Experimental flow chart
其中模型参数调整包括dropout 系数、正则化系数、batch_size。迭代次数为2 000,同时在模型训练过程中调用tensorflow 中的ModelCheckpoint 函数对模型训练过程中测试集损失值最小时的模型参数进行保存。最后利用验证集对各个最优模型进行预测性能比较。实验过程中不变参数如表1所示。

表1 不变参数表Tab.1 Table of invariant parameters
3.3 数据处理和数据集划分
因为数据是从现场直接采集的,受设备故障以及人为操作失误等问题而导致数据可能存在缺失或者异常值,因此在使用窗口函数对数据划分前需要对数据进行以下处理:
(1)检测数据中的异常值(超大值、负值、零值)并进行删除留下空缺。
(2)利用线性插值法补齐缺失值,线性插值法的计算公式入式(1)所示:
式中:xk为要补齐的值;xw为xk前面最近的已知数据;xr为xk后面最近的已知数据。
(3)将数据进行标准化处理,可以加快梯度下降速度。如式(2)所示
式中:x′为标准化后的值;xmean为本指标序列平均值;xstd为本指标序列的标准偏差。
在对数据进行基本处理后需要对数据进行划分。由于顺序模型和encoder-decoder 模型的输入不同。顺序模型的输入为厂出水处历史数据+厂入水处历史数据,encoder 输入为厂入水处历史数据,decoder 输入为厂出水处历史数据,两种框架的输出均为厂出水处未来预测值。本文从两个时间维度上对模型性能进行分析,其中短期预测模型的输出为未来单步数据,长期预测时模型输出为未来20 步的数据。本文模型输入均为历史20步,数据流如图5所示。
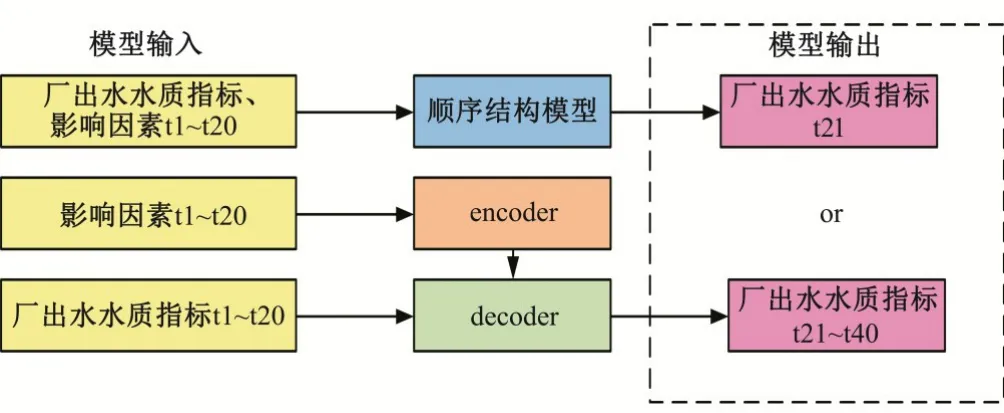
图5 模型输入输出数据流图Fig.5 Model input and output data flow diagram
将处理好的数据集按照6∶2∶2划分为训练集、测试集、验证集。训练集用于训练模型,测试集对训练模型进行筛选,找出最佳的参数,验证集仅用于对训练好的模型进行性能评估。
3.4 实验数据和实验环境
研究所使用的数据来源于吉林省某污水厂,记录了2020年1月1日至2020年3月30日的相关数据,包括厂出水处数据(出水COD、NH3-N、TP、TN)和影响因素(进水COD、入水NH3-N、温度、降水量)。采样间隔为30 min,共计4 320 个时间点数据。本文采用以上数据对模型进行训练及预测,以预测厂出水处数据为目标,故将出水处水质指标的未来预测值作为标签向量。数据经过划分后短期预测中训练集数为2 580,测试集及验证集数量为860;在长期预测中训练集数为2 568,测试集及验证集数量为856。
实验硬件环境为Intel i7-11800H 处理器,16G 内存,NVIDIA GTX3070 显卡。软件环境为jupyter notebook,使用Python 语言编写程序,使用Google研发的tensorflow 机器学习接口搭建神经网络,使用sklearn库计算各个指标。
4 结果和分析
为了对比本文encoder-decoder 结构神经网络和顺序结构神经网络的预测效果,选择拟合优度(R2)、均方根误差(RMSE)对模型进行性能评价,使用公式如下所示。
R2的值在0~1 之间,越接近1 表明模型的拟合程度越高。RMSE表示预测值与真实值偏差的平方和与观察次数比值的平方根,其值越小表示预测模型的偏差程度越小。
4.1 短期预测结果分析
将验证集输入到训练好的各个模型中得到预测值,将预测值和真实值进行对比,图6 为验证集中100 步的出水COD 通过各个模型单步预测效果图。
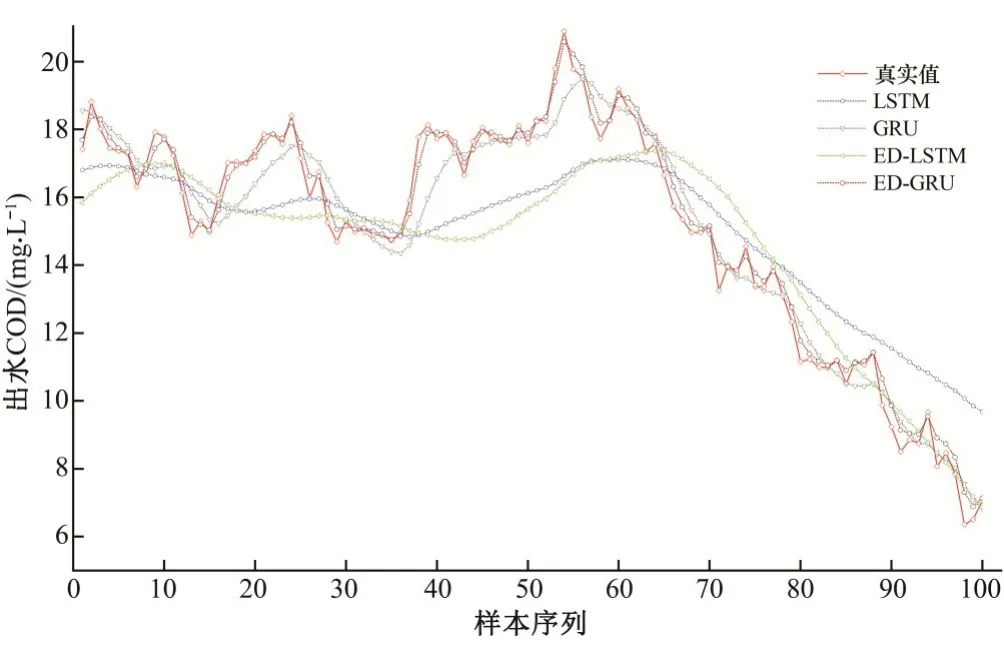
图6 模型预测效果对比图Fig.6 Comparison of model prediction results
通过4 种模型预测对比图(图6)可看出,4 种模型的预测值与真实值的变化趋势基本一致,其中ED-GRU、GRU 模型的预测曲线和真实值曲线拟合度较高,说明ED-GRU、GRU 模型对复杂序列有较强的特征提取能力,不仅能准确预测水质变化趋势,还能对水质局部变化进行较好的预测。最终通过两种指标量化各个出水指标预测效果,表2为短期预测指标表。

表2 模型短期预测指标对比表Tab.2 Comparison of model short-term forecast indicators
由表2可以得出如下结论:
(1)ED-GRU 污水出水预测模型中的出水COD、出水NH3-N、出水TP、出水TN 指标的均方根误差为0.755 1、0.219 7、0.073 4、0.314 6,拟合优度系数为0.901 3、0.933 2、0.916 7、0.953 2。结果证明,ED-GRU 在短期预测时的预测结果与真实值的误差小、拟合程度高、水质预测精度更高。
(2)encoder-decoder 结构的两种污水出水预测模型与传统顺序结构的LSTM、GRU 相比,预测进度有所提升。特别是EDGRU 模型相比顺序结构的GRU 模型均方根误差分别降低了13.95%、38.42%、25.25%、11.92%,拟合优度增加了5.25%、2.66%、10.75%、2.25%。结构证明encoder-decoder 结构可以提升复杂水质环境下的污水厂出水水质预测模型的预测准确度。
(3)ED-GRU 模型比同结构下的ED-LSTM 模型预测准确度高,这是由于GRU具有更少的门控单元,因此参数更少、计算量更小、训练速度更快,可以降低由训练过程中的过拟合现象造成的影响并提高迭代速度,因此ED-GRU 模型具有更高的泛用性。
综上所述,研究提出的ED-GRU 模型在预测出水COD、出水NH3-N、出水TP、出水TN水质指标在短期预测有着较高的预测精度。对比LSTM、GRU 和ED-GRU 模型,污水出水预测模型ED-GRU在短期预测精度上有不同程度的提升。
4.2 长期出水水质预测结构分析
对于模型在长期预测有效性及稳定性进行评估,将模型输出设置为预测未来20步,图7为一次预测时各个模型对出水TP的预测效果。
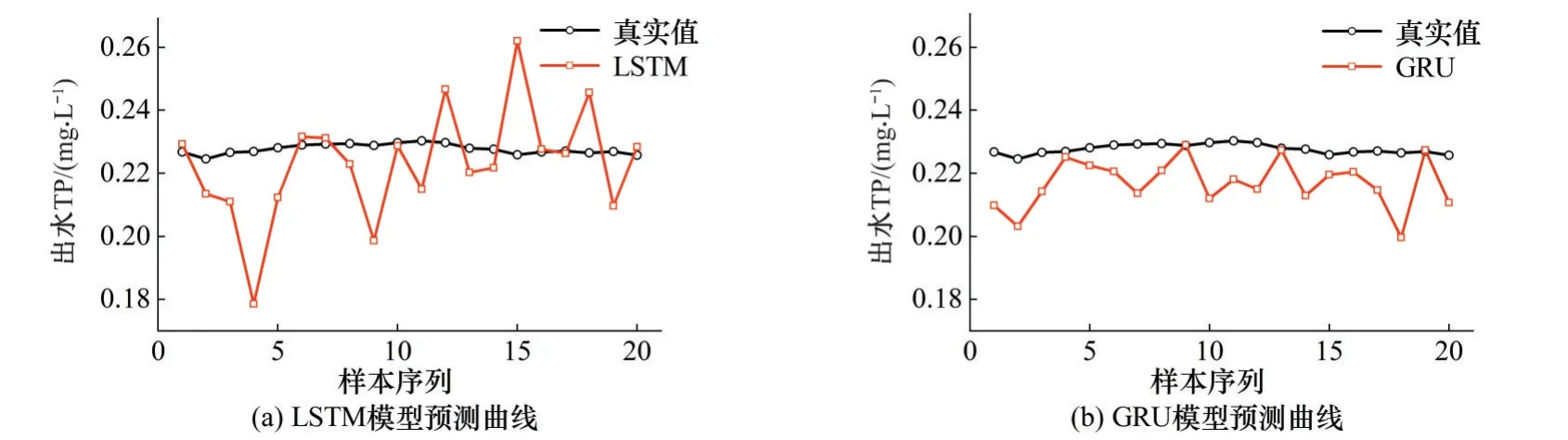
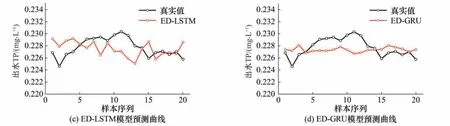
图7 模型预测值与真实值对比图Fig.7 Plot of model predicted versus true values
图7顺序结构与encoder-decoder 结构对比中的真实值是相同的,为了更直观对比模型性能对图标幅值进行了修改,从0.170~0.270 到0.220~0.235。其中顺序结构在进行长序列预测时,部分点偏离真实值,预测效果不佳。encoder-decoder 结构模型进行长序列预测时,能较好的预测出水质趋势,相比于顺序结构偏离较小,预测效果有一定提升。
通过表3可知:

表3 模型长期预测指标对比表Tab.3 Comparison of model long-term forecast indicators
(1)时间步长对预测结果影响较大,在长期预测时模型准确度相比短期预测准确度都有着较大的差距。模型在以较长时间步长进行预测时,会将上一个预测结果考虑在内,所以在长步长预测时,模型预测准确性有所下降。
(2)ED-GRU 污水出水预测模型中的出水COD、出水NH3-N、出水TP、出水TN 指标的均方根误差为1.720 4、1.768 9、0.447 8、0.831 6,拟合优度系数为0.484 9、0.550 7、0.450 2、0.759 5。结果证明,ED-GRU 在短期预测时的预测结果与真实值的误差小、拟合程度高、水质预测精度高。
(3)ED-GRU 和ED-LSTM 模型相比顺序结构的GRU 和LSTM模型准确度更优。其中ED-GRU相比顺序结构GRU模型均方根误差分别降低了40.21%、27.95%、34.16%、25.22%,拟合优度增加了65.38%、53.69%、38.18%、17.44%。说明encoderdecoder 结构能够缓解长步长预测时的模型误差迅速增加的趋势,实现更为准确的污水出水水质长期预测。
综上所述,研究提出的ED-GRU 模型不论时短期预测还是长期预测,在对复杂水质环境下的污水出水预测有着较高的预测精度。对比常用的顺序结构的LSTM 和GRU 和ED-LSTM 水质预测模型,ED-GRU 在预测精度上有不同程度的提升,说明ED-GRU 模型预测的方法在对于复杂程度高、高非线性的数据具有更好的拟合能力和鲁棒性。特别是在长期预测时encoderdecoder结构的模型对长步长预测有着更强的特征提取能力。
5 结论
(1)提出了一种基于encoder-decoder 结构的神经网络,实验表明encoder-decoder 结构的神经网络比顺序结构神经网络有更好的预测效果,特别是ED-GRU 网络在对本例CASS 工艺污水出水COD、出水NH3-N、出水TP、出水TN 指标预测中取得了良好的效果,相比顺序结构GRU 模型在短期预测中RMSE降低11.92%~38.42%,R2增加2.25%~10.75%,能够预测出水质在短期内的变化趋势;在长期预测中RMSE降低25.22%~41.21%以上,R2增加17.44%~65.38%,可以预测出水质在未来变化的总体趋势。
(2)采取了多指标输入来预测多指标输出策略,将影响污水处理过程的环境因素引入,这可以让模型在复杂环境中应用。本文使用污水厂出水入水处两点数据进行预测,可以根据污水处理厂的实际情况进行分析并采取不同的预测指标进行预测,具有一定实际意义。
(3)在未来的工作中,可以尝试更多的算法对模型预测效果进行提升特别是在长期预测中,并且可以为将来神经网络和预测控制模型进行结合,根据污水出水预测数据对污水处理工艺进行优化。
猜你喜欢
数学小灵通(1-2年级)(2023年1期)2023-02-10
娃娃乐园·综合智能(2022年7期)2022-07-16
中国应急管理科学(2022年2期)2022-05-23
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2021年20期)2021-11-26
小读者(2019年20期)2020-01-04
南方周末(2019-12-05)2019-12-05
资源节约与环保(2018年1期)2018-02-08
河北科技大学学报(2015年5期)2015-03-11
电测与仪表(2014年2期)2014-04-04
