
作业车间调度的块结构邻域搜索遗传算法
2021-11-10 04:32薛玲玲
计算机集成制造系统 2021年10期
薛玲玲
(1.中国科学院沈阳自动化研究所 机器人学国家重点实验室,辽宁 沈阳 110169;2.中国科学院 网络化控制系统重点实验室,辽宁 沈阳 110169;3.中国科学院 机器人与智能制造创新研究院,辽宁 沈阳 110169;4.中国科学院大学,北京 100049)
0 引言
作业车间调度问题(Job-shop Scheduling Problem, JSP)作为生产调度管理系统中的一种重要类型,属于典型的NP-hard问题[1]。作业车间调度通过给出合理的生产计划,保证生产顺利而有序地进行,从而实现提高生产效率和满足用户需求的价值。因此,JSP一直受到学术界和工业界的热切关注。
作为一类典型的组合优化问题,当JSP规模较小时,可以采用线性规划法[2]、分支定界法[3]等精确法寻找最优解。考虑到其NP-hard的特性,当生产规模增加时,会造成解空间的组合爆炸,采用精确法很难在可接受的时间内找到合适的解,而以智能优化算法为代表的近似法,以其求解速度快、求解质量高等优点,成为了求解JSP更有价值的实用方法。文献[4-5]从提高机器空闲时间的角度出发,对文献[6]提出的邻域搜索遗传算法的邻域结构进行改进,分别提出了基于空闲时间的邻域结构和新型的邻域结构;文献[7]提出一个离散的粒子群优化算法求解完工时间最小化的JSP;文献[8]提出一个基于关键路径指导的Giffler & Thompson(GT)交叉算子,能够根据父代个体的关键路径识别重要的遗传信息;文献[9]分别采用局部搜索策略和多交叉方法对遗传算法的变异和交叉操作进行改进,将改进后的遗传算法用于求解JSP;文献[10]将遗传灰狼算法与变邻域搜索算法相结合,求解总能耗成本与总完工时间最小的低碳JSP;文献[11]提出一种遗传算法与基于邻域结构的邻域搜索算法相结合的模因算法求解JSP;文献[12]提出一个基于模因算法的三阶多种群混合算法。通过对当前已有方法的研究可知,采用单一的优化算法求解JSP时,总存在搜索空间有限导致早熟收敛的问题。将全局搜索能力强的算法与局部搜索算法结合起来,既能加快算法的收敛速度,又能避免陷入局部最优。不同算法的结合使用是当前最常使用的改进方向。
本文结合JSP的特点,提出一种基于块结构邻域搜索的遗传算法。该算法为提高群体中个体的适应度,延迟算法早熟,引入子代选择机制[13]。通过分析遗传算法中编码方式可知,采用基于工序的编码方式生成的个体,在进行随意位置的交换、移动等操作时都不会生成不可行个体,因此将基于工序的编码方法引入到邻域搜索过程中。最后,将本文提出的算法与其他现有算法在基准算例上进行对比,验证算法的有效性。
1 作业车间调度问题描述
JSP可以描述为N个工件在M台机器上加工,工件在不同机器上的加工时间已知,且工件的加工路径确定。如图1所示,假设有两个工件Job1,Job2在4台机器上加工。其中Job1的加工顺序为M1→M3→M2→M4,Job2的加工顺序为M2→M1→M4→M3。

下面对作业车间调度问题进行如下假设:
(1)所有工件在零时刻可得;
(2)同一工件不能同时在不同机器上加工,同一机器同一时间只能加工一个工件;
(3)工件在某一机器上一旦开始加工不能停止;
(4)工件上一步工序加工完成之后才能加工下一步工序;
(5)机器只有加工完当前工序才能加工下一个工序;
(6)本文假设工件在不同机器之间的转运时间忽略不计,仅考虑工件在机器上的加工时间。
相关概念如表1所示。

表1 作业车间调度问题相关概念
以最大完工时间最小化为优化目标,目标函数为
Cmax=min max (ctji)。
(1)
2 改进的邻域搜索遗传算法
本文将具有隐形并行、全局搜索能力强的遗传算法与专注个体局部搜索的邻域搜索算法相结合,提出一种基于块结构邻域搜索的遗传算法,算法流程如图2所示。该算法主要采用基于工序的编码方法和主动解码方法对个体进行编码和解码,利用解码后工序的开始加工时间对个体进行排序,使同一机器上工序加工顺序与实际加工顺序一致;采用精英个体保存策略保存每一代最优个体;遗传操作中采用二元锦标赛选择个体,交叉操作采用改进的基于工序的交叉操作,并将交叉操作嵌入到子代选择机制中;采用互换变异与逆转变异两种变异方式生成变异个体。其中,邻域搜索算法中的邻域结构采用改进的基于块结构的邻域构建方法生成。
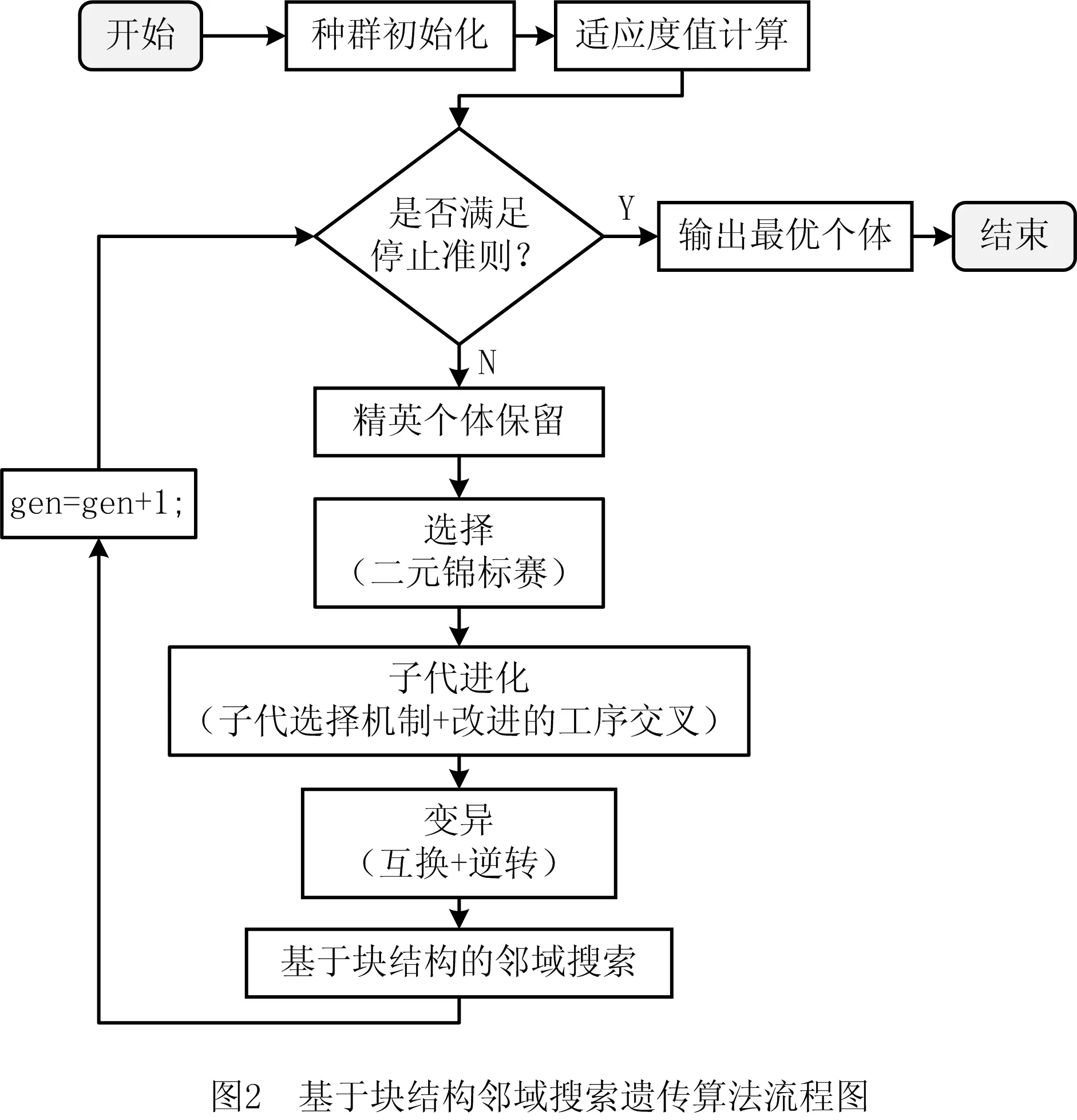
3 邻域结构生成方法
3.1 邻域结构
与采用随机生成邻域个体的方法相比,采用基于关键路径生成的邻域结构,对于求解以最小化最大完工时间的JSP能够更好地提高邻域搜索质量[14-15]。根据对基于关键工序块的邻域结构构建方法的研究可知,交换块内相邻工序不会缩短最大完工时间[16]。
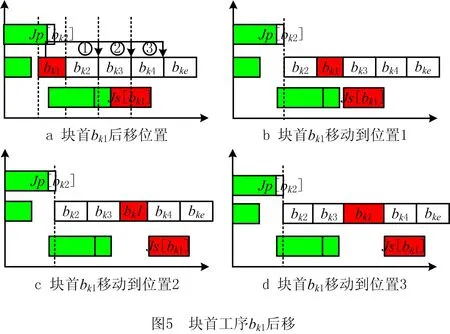
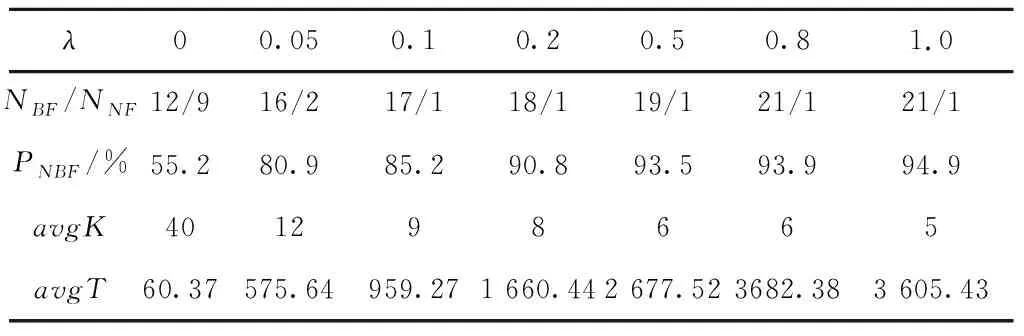
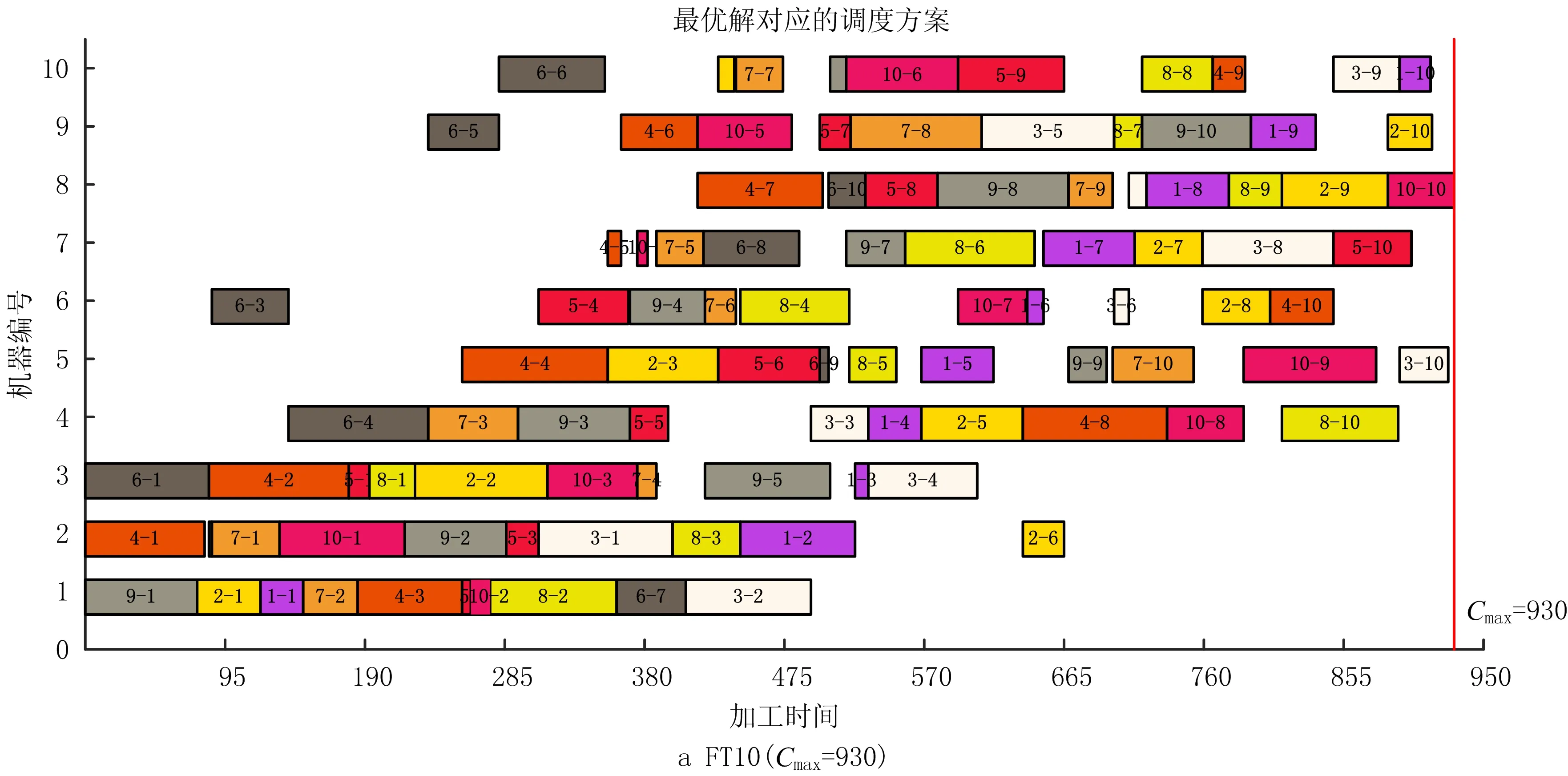
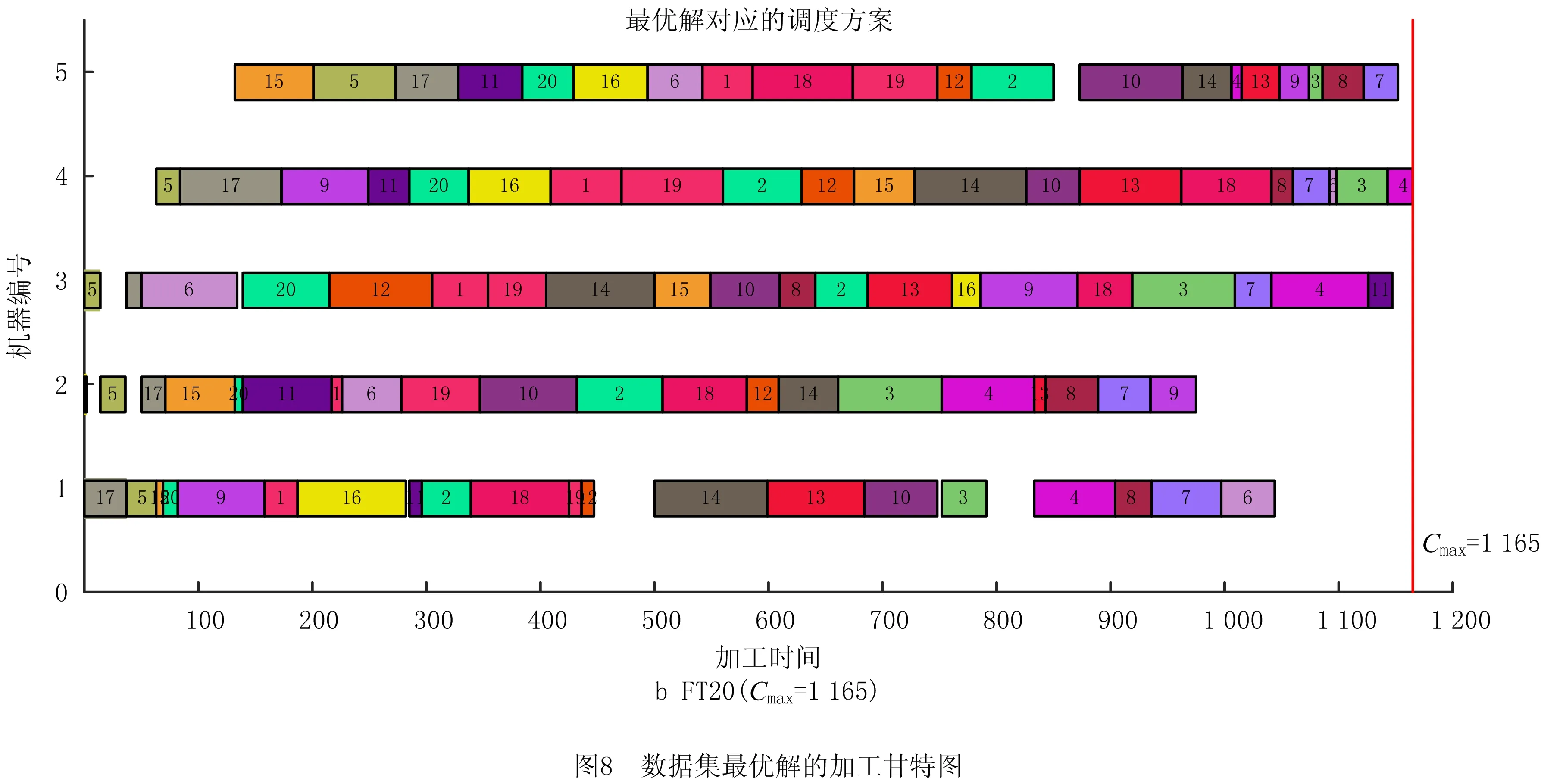
本文主要采用工序交换和工序移动两种方法构建邻域结构,工序移动又包括工序前移和工序后移。假定关键路径上两工序u,v,工序u在v之前加工,即满足ST(u) 工序交换、工序前移和工序后移对应的操作分别为: EX(u,v):交换工序u和工序v的位置; moveA(v,u):将工序v移动到工序u的前面; moveB(u,v):将工序u移动到工序v的后面。 结合工序编码的特点可知,采用基于工序编码生成的邻域不存在不可行解的情况,因此不需要进行可行性分析。但在生成的邻域个体集中,可能存在邻域个体之间或邻域个体与原个体之间生成的调度方案相同的情况,即邻域个体的冗余。为减少冗余个体的生成,本文提出以块首工序或块尾工序为中心,将其与块内工序的移动和交换作为一个邻域生成单元,通过工序间位置关系的分析,选择合适的邻域生成操作,减少冗余的邻域个体。图3给出了一个以块首工序bk1为中心,该中心通过与块内工序bkj交换、移动生成的邻域结构单元。接下来,分别从与块首/块尾相邻工序生成的邻域单元以及非相邻两种情况,对邻域的生成进行分析。 由关键工序块的概念可知,如果存在块首bk1的工序紧前工序Jp[bk1]和块尾bke的工序紧后工序Js[bke],则一定在关键路径上。由此可知,与块内工序的交换有可能减小最大完工时间[16-19]。相邻工序用u,v表示,根据工序u,Js[u],v,Jp[v]的位置关系对工序交换和移动前后得到的调度方案进行分析。 (1)若Jp[v],Js[u]均不在u,v之间,即工序的位置信息满足pos(Jp[v])∉[pos(u),pos(v)],pos(Js[u])∉[pos(u),pos(v)],则工序交换,前移和后移生成的调度方案相同。 证明如果原调度方案S中Jp[v],Js[u]均不在工序u,v之间,在不考虑其他加工工序时,按照开始加工时间可以将工序加工顺序简化为图4a所示的加工顺序:Jp[v]→u→v→Js[u]; 工序u,v交换结果(如图4b): EX(u,v)=Jp[v]→v→u→Js[u]; 工序u后移结果(如图4c): moveB(u,v)=Jp[v]→v→u→Js[u]; 工序v前移结果(如图4d): moveA(v,u)=Jp[v]→v→u→Js[u]。 由此可知,工序交换、工序前移和工序后移生成相同的调度方案,因此生成邻域个体时,3个操作只需选择一个即可。 (2)若Jp[v]不在工序u,v之间,Js[u]在工序u,v之间,即工序的位置信息满足pos(Jp[v])∉[pos(u),pos(v)],pos(Js[u])∈[pos(u),pos(v)],则工序交换与工序前移生成的调度方案相同,工序后移与原调度方案相同。 证明根据条件可知,工序u,v,Jp[v],Js[u]的加工顺序为:Jp[v]→u→Js[u]→v; 工序u,v交换结果为: EX(u,v)=Jp[v]→v→Js[u]→u=> Jp[v]→v→u→Js[u]; 工序v前移结果为: moveA(v,u)=Jp[v]→v→u→Js[u]; 工序u后移结果为: moveB(u,v)=Jp[v]→Js[u]→v→u=> Jp[v]→u→v→Js[u] =Jp[v]→u→Js[u]→v。 由此可知,工序交换与工序前移生成的调度方案相同,工序后移生成的调度方案与原调度方案相同;生成邻域时选择工序交换或工序前移即可。 (3)若Jp[v]在工序u,v之间,Js[u]不在工序u,v之间,即工序的位置信息满足pos(Jp[v])∈[pos(u),pos(v)],pos(Js[u])∉[pos(u),pos(v)],则工序交换与工序后移生成的调度方案相同,工序前移与原调度方案相同。 证明根据条件可知,工序u,v,Jp[v],Js[u]的加工顺序为:u→Jp[v]→v→Js[u]; 工序u,v交换结果为: EX(u,v)=v→Jp[v]→u→Js[u]=> Jp[v]→v→u→Js[u]; 工序v前移结果为: moveA(v,u)=v→u→Jp[v]→Js[u]=> Jp[v]→u→v→Js[u] =u→Jp[v]→v→Js[u]; 工序u后移结果为: moveB(u,v)=Jp[v]→v→u→Js[u]。 由此可知,工序交换与工序后移生成的调度方案相同,工序前移生成的调度方案与原调度方案相同;生成邻域时选择工序交换或工序后移即可。 (4)若Jp[v],Js[u]均在工序u,v之间,即工序的位置信息满足pos(Jp[v])∈[pos(u),pos(v)],pos(Js[u])∈[pos(u),pos(v)],则工序交换与工序前移生成的调度方案相同,工序后移生成的调度方案与原调度方案相同。 证明根据条件可知,如果工序Jp[v],Js[u]均在工序u,v之间,则可知stJs[u]=stv,且pos(Js[u]) 工序u,v交换结果为: EX(u,v)=v→Jp[v]→Js[u]→u=> Jp[v]→v→u→Js[u]; 工序v前移结果为: moveA(v,u)=v→u→Jp[v]→Js[u]=> Jp[v]→u→v→Js[u] =u→Jp[v]→Js[u]→v; 工序u后移结果为: moveB(u,v)=Jp[v]→Js[u]→v→u=> Jp[v]→u→v→Js[u] =u→Jp[v]→Js[u]→v。 由此可知,工序前移与工序后移生成的调度方案与原调度方案相同;生成邻域时仅进行工序交换即可。 由于块首工序与块内工序交互生成邻域过程和块尾工序与块内工序交换生成邻域过程相似,选择分析块首工序与块内工序交互过程。通过分析3.2节的结果可知,工序移动存在与原调度方案相重合或与交换生成邻域方案相重合的情况。因此,首先对工序的有效移动条件进行分析。 3.3.1 块首/块尾工序有效移动条件分析 以块首工序为例,对工序的有效移动条件进行分析。假定调度方案中,存在如图5a所示的关键工序块COB=[bk1,bk2,bk3,bk4,bke],且块首bk1的工序紧后工序Js[bk1]位于bk3与bk4之间,则可知块首工序bk1有3个后移位置1、2、3。第1和第2种工序后移结果分别如图5b和图5c所示;第3种工序后移生成的调度方案如图5d所示,与第2种移动结果相同。 因此可以得出一般化结论:块首bk1移动到块内工序bkj之后的条件为pos(Js[bk1])>pos(bkj);同理可得,块尾bke移动到块内工序bkj之前的条件为pos(Jp[bke]) 3.3.2 块内工序有效移动条件分析 以图6a所示的调度方案为例,对块内工序有效移动条件进行分析。进行前移的块内工序有bk2,bk3,bk4,其中bk2为块首相邻工序,由工序序列可知其工序紧前工序Jp[bk2]与块首工序的位置关系满足pos(Jp[bk2])>pos(bk1),移动结果如图6b所示,生成新个体的调度方案与原个体相同;工序bk3的紧前工序Jp[bk3]与块首工序的位置关系满足pos(Jp[bk3]) 综合以上分析,满足块内工序bkj前移条件为pos(Jp[bkj]) 同理,块内工序bkj后移条件为pos(Js[bkj])>pos(bke)。 3.3.3 与块首非相邻工序邻域的生成过程 根据块首工序后移条件与块内工序前移的条件,给出满足块首bk1与块内工序bkj的邻域生成的条件: (1)若pos(Js[bk1]) 证明由于pos(Js[bk1]) 由于pos(Jp[bkj])>pos(bk1),即移动结果如图6b所示,不满足块内工序bkj有效前移条件; 因此仅需对工序交换进行判断,假定满足给定条件的加工顺序为: bk1→Js[bk1]→bk2→…→Jp[bkj]→bki→…→ bkj→…→bke, 则工序交换结果为: EX(bk1,bkj)=bkj→Js[bk1]→bk2→…→ Jp[bkj]→bki→…→bk1→…→bke =Jp[bkj]→bk1→bk2→…→bkj→bki→…→ Js[bk1]→…→bke。 可知,关键工序块内工序加工顺序不变,与原调度方案相同。因此,该条件下不需要生成新邻域个体。 (2)若pos(Js[bk1]) 证明由于pos(Js[bk1]) 由于pos(Jp[bkj]) 假定满足给定条件的加工顺序为: Jp[bkj]→bk1→Js[bk1]→bk2→…→bki→…→ bkj→…→bke, 则工序交换结果为: EX(bk1,bkj)=Jp[bkj]→bkj→Js[bk1]→bk2 →…→bki→…→bk1→…→bke =Jp[bkj]→bkj→bk1→bk2→…→bki→… →Js[bk1]→…→bke; 工序前移结果为: moveA(bkj,bk1)=Jp[bkj]→bkj→bk1→ Js[bk1]→bk2→…→bki→…→bke。 可知,工序交换和块内工序前移生成的调度方案相同。 因此,该条件下仅需选择工序交换或块内工序前移即可。 (3)若pos(Js[bk1])>pos(bkj),pos(Jp[bkj])>pos(bk1),即满足块首工序有效后移,不满足块内工序有效前移的条件,则选择工序交换或块首工序后移之一即可。 证明由条件pos(Js[bk1])>pos(bkj),即移动结果如图5c所示,满足块首有效后移条件; 由于pos(Jp[bkj])>pos(bk1),即移动结果如图6b所示,不满足块内工序bkj有效前移条件; 假定满足给定条件的加工顺序为: bk1→bk2→…Jp[bkj]→bkj→bki→ Js[bk1]→…→bke, 则可知工序交换结果为: EX(bk1,bkj)=bkj→bk2→…Jp[bkj]→bk1→ bki→Js[bk1]→…→bke =Jp[bkj]→bk2→…→bkj→bk1→ bki→Js[bk1]→…→bke; 块首工序后移结果为: moveB(bk1,bkj)=bk2→…Jp[bkj]→bkj →bk1→bki→Js[bk1]→…→bke。 可知,工序交换和块首工序后移生成的调度方案相同。 因此,该条件下选择工序交换与块首工序后移之一即可。 (4)若pos(Js[bk1])>pos(bkj),pos(Jp[bkj]) 证明由条件pos(Js[bk1])>pos(bkj),即移动结果如图5c所示,满足块首有效后移条件; 由条件pos(Jp[bkj]) 假定满足给定条件的加工顺序为: Jp[bkj]→bk1→bk2→…→bkj→bki →Js[bk1]→…→bke, 则工序交换结果为: EX(bk1,bkj)=Jp[bkj]→bkj→bk2→…→ bk1→bki→Js[bk1]→…→bke; 块首工序后移结果为: moveB(bk1,bkj)=Jp[bkj]→bk2→…→bkj→ bk1→bki→Js[bk1]→…→bke; 块内工序bkj前移结果为: moveA(bkj,1)=Jp[bkj]→bkj→bk1→bk2 →…→bki→Js[bk1]→…→bke。 3种情况下生成的调度方案均不相同且与原调度方案不同,由此可知,可以进行工序交换、块首工序后移和块内工序前移3种不同操作。 3.3.4 与块尾非相邻工序邻域的生成过程 同理,根据块尾工序前移与块内工序后移的条件,给出4种不同条件下块尾工序与块内工序交互生成邻域结构的条件: (1)若pos(Jp[bke])>pos(bke),且pos(Js[bkj]) (2)若pos(Jp[bke])>pos(bke),pos(Js[bkj])>pos(bke),即不满足块尾bke前移条件,但满足块内工序bkj后移的条件,则选择工序交换或块内工序后移之一即可。 (3)若pos(Jp[bke]) (4)若pos(Jp[bke]) 为验证算法的有效性,采用国际上通用的作业车间调度问题数据集作为测试数据集。实验平台为计算机处理器主频为1.80 GHz,内存为8 GB,采用MATLAB编程实现。 为分析进入局部搜索个体占比λ的影响,取λ∈{0,0.05,0.1,0.2,0.5,0.8,1},以通用的LA数据集中的LA01~LA20等20个数据集和FT的3个数据集为基准算例,以遗传算法为基本框架,结合禁忌局部搜索算法对所选取的数据集进行测试,从而确定合适的占比λ。其中,每个数据集独立运行10次。 参数设置如下: (1)初始种群随机生成,种群规模 其中:N为待加工工件个数;M为数据集中机器个数;Npop表示数据集的种群规模;Npop1表示进入局部搜索的种群规模。 (2)优秀个体占种群规模的前2%; (3)交叉概率Pc=0.8,变异概率Pm=0.45, (4)终止条件:总迭代次数T=500,最优适应度值连续L=30代不变或找到最优目标值。 算法的测试结果如图7所示。由图7可知,λ占比越大,即进入局部搜索的个体越多,得到最优解的概率越大。当λ=0时,即仅采用基本的遗传算法,23个数据集中有12个算例完全没有找到最优解;当λ=1时,即种群中所有个体均进行局部搜索时,有22个算例找到最优解(仅算例LA20未找到最优解)。且由图7可以看出,随着λ值的增加,数据中能够找到最优解的概率会随之增加,但算法运行时间也会随之增加。因此,为均衡算法的寻优效果与运算时间,λ值取0.1~0.2之间某一值即为合适,本文取λ=0.15。 不同λ值下数据集运行结果如表2所示。表2中:NBE表示N次运行得到最优解的次数,NBF表示所有数据集N次运行均找到最优解的数据集个数;NNF表示所有数据集N次运行均未找到最优解的数据集个数;PNBF表示所有数据集N次运行找到最优解的概率;avgK表示不同λ值算法的平均迭代次数。实验中数据集共有23个,运行次数N=10。 表2 不同λ下数据集运行结果分析 由4.1节中的实验结果可知,进入局部搜索的个体占比λ=0.15比较合适,即N1=0.15×N。同时,在给出的LA和FT数据集中存在一些易于找到最优解的实例集,无法充分验证算法的寻优能力。因此,本文采用文献[20]中所用9个较难找到最优解的数据集作为测试数据集,算法参数设置与4.1节相同,算法的运算结果如表3所示。表3中:C*表示当前已知最优解;Cbest表示算法独立运行10次得到的最优解;e表示算法找到的最优解Cbest与当前已知最优解C*之间的相对偏差, 表3 不同算法运行结果统计 续表3 (2) 首先,采用平均相对偏差MRE从整体的角度比较算法的性能。本文所提算法的MRE值为0.451,其他6篇文献所提算法的MRE分别为0.456,0.384,0.518,3.842,1.565和3.075。由此可知,本文算法在整体性能上优于其中5种算法,略逊于文献[5]提出的算法。主要原因在于算法的求解质量不仅受迭代次数和终止条件的影响,还受到种群规模的影响。为保证算法的运行效率,本文将种群规模选取为数据集的工件数和机器数的常数倍。如果增加迭代次数或增加种群规模,能够进一步提高终解质量。 另外,以本文所提算法找到的最优解作为基准,与其他算法找到的最优解进行对比,结果如表4所示,表中:NB表示本文算法找到的最优解优于对比算法的数目;NW表示本文算法找到的最优解差于对比算法的数目;NE表示本文算法找到的最优解与对比算法相同的数目。比较本文算法与基于邻域结构改进相关文献[4-5]的优劣解。与文献[4]相比,优于文献[4]的最优解NB=2,差于文献[4]的最优解NW=3,文献[4]算法性能略优于本文提出的算法;与文献[5]相比,两者优于解与差于解数目相当,因此性能相当。 表4 本文算法与其他算法最优解优劣对比分析 与文献[7]提出的离散粒子群算法以及文献[10]所提出的混合灰狼算法相比,本文找到的最优解略优于文献[7],且明显优于文献[10],可知本文算法的求解性能优于文献[7]与文献[10]所提算法。与两个改进的遗传算法[8-9]相比,本文所提算法找到的最优解个数明显更多。 综上分析可知,将遗传算法与局部搜索算法相结合能够显著提高算法的局部搜索能力,实验结果也表明了本文所提算法的有效性。 最后以数据集FT10和FT20为研究对象,分别给出算法找到的最优解对应的工件加工甘特图,如图8所示。对于FT10数据集,算法在第37代开始收敛;对于FT20数据集,算法在第73代开始收敛。 本文提出一种基于块结构的邻域搜索遗传算法,该算法结合了邻域搜索算法的局部搜索和遗传算法的全局搜索的优势,能够有效地解决传统遗传算法在求解车间调度问题中种群多样性差、易早熟等问题。 本文在基于工序编码的工序序列上,采用基于关键工序块的邻域生成方法构建邻域结构,有效地避免了不可行解的产生。为了解决邻域构建中邻域的冗余问题,本文提出了以关键工序块中块首工序或块尾工序为中心,将中心工序与块内工序的交换和移动作为邻域单元。通过分析工序在工序序列中的位置信息,判断邻域生成前后是否存在相同的调度方案,提出了邻域单元的冗余性判据条件。同时,针对传统遗传算法在算法进化过程中由于种群进化过程中个体相似度的增加,采用子代选择机制对遗传操作生成的子代个体进行寻优,提高子代质量。 通过将该算法在不同规模的JSP上进行测试,对算法的有效性进行了验证。当前的工作主要是算法的改进及对基准问题的测试,初步验证了算法的可行性和有效性,下一步工作将主要集中在算法在实际场景的应用,以及对异常事件的处理。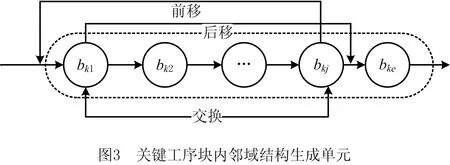
3.2 与块首/块尾相邻工序的邻域生成过程

3.3 与块首/块尾非相邻工序的邻域生成过程

4 实验与分析
4.1 局部搜索个体规模对车间调度性能的影响

4.2 算法有效性验证实验


5 结束语
猜你喜欢
昆钢科技(2022年2期)2022-07-08吉林大学学报(理学版)(2020年3期)2020-05-29石材(2020年4期)2020-05-25建材发展导向(2019年10期)2019-08-24自动化学报(2018年7期)2018-08-20石油地球物理勘探(2017年2期)2017-11-23中央民族大学学报(自然科学版)(2017年1期)2017-06-11统计与决策(2017年2期)2017-03-20周口师范学院学报(2016年5期)2016-10-17工程建设与设计(2016年1期)2016-02-27
